Take this with a grain of sand, these are only initial figures. I am using a combination of IOMeter for Windows and fio for Linux.
Baseline redundancy and caching, no storage profiles used, only using vSAN as a datastore (I’ll do the other options later)
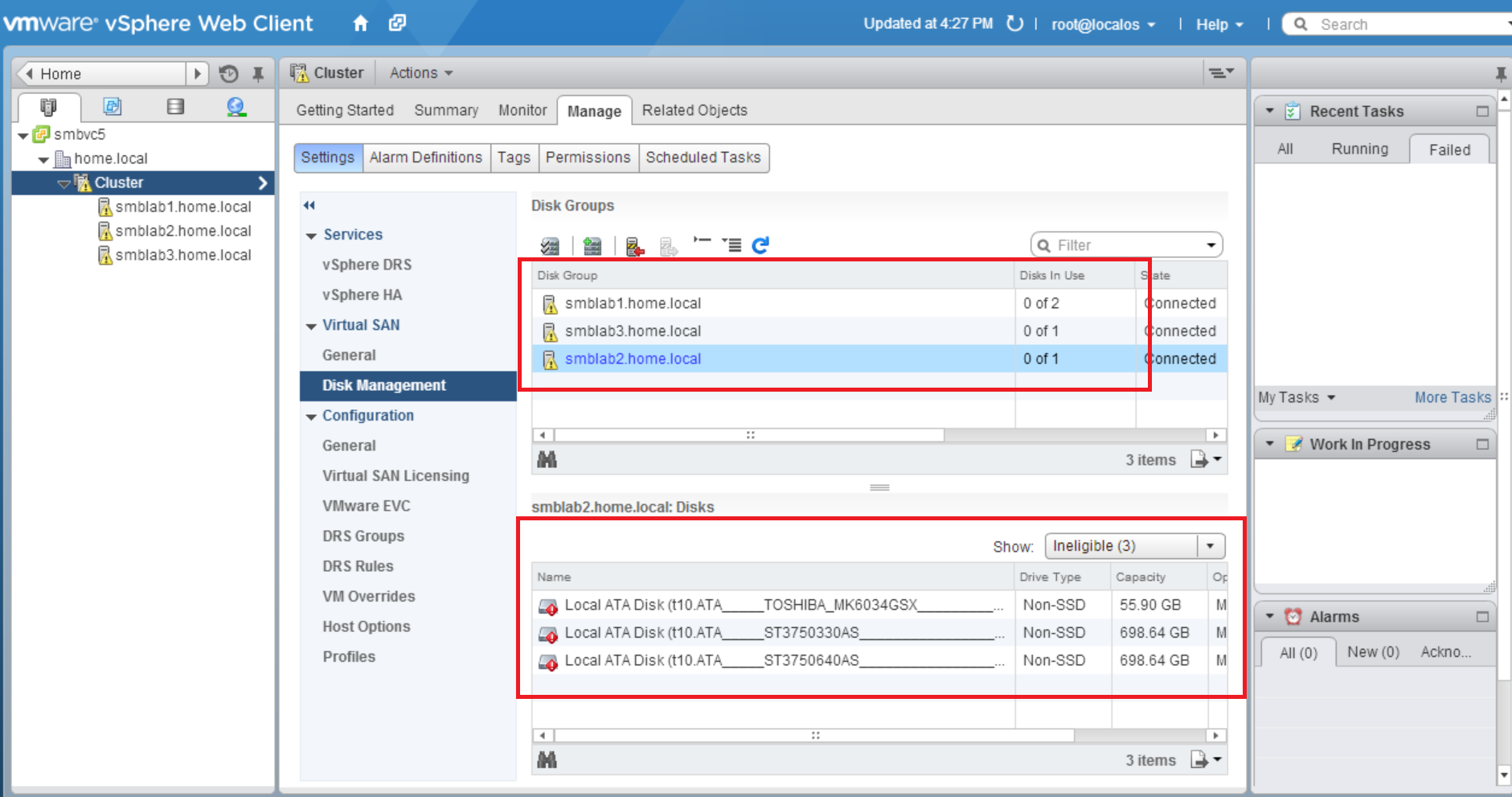
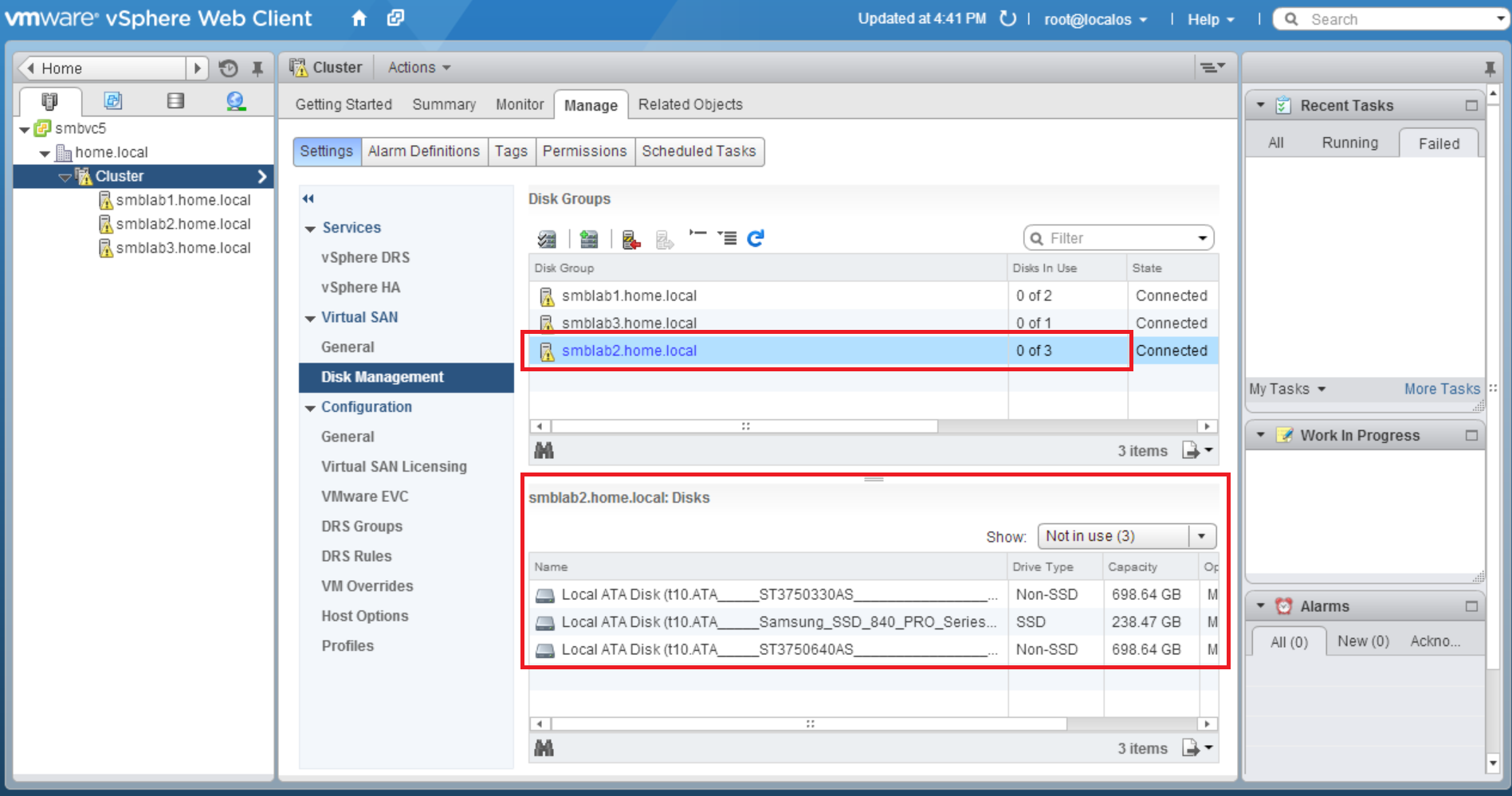
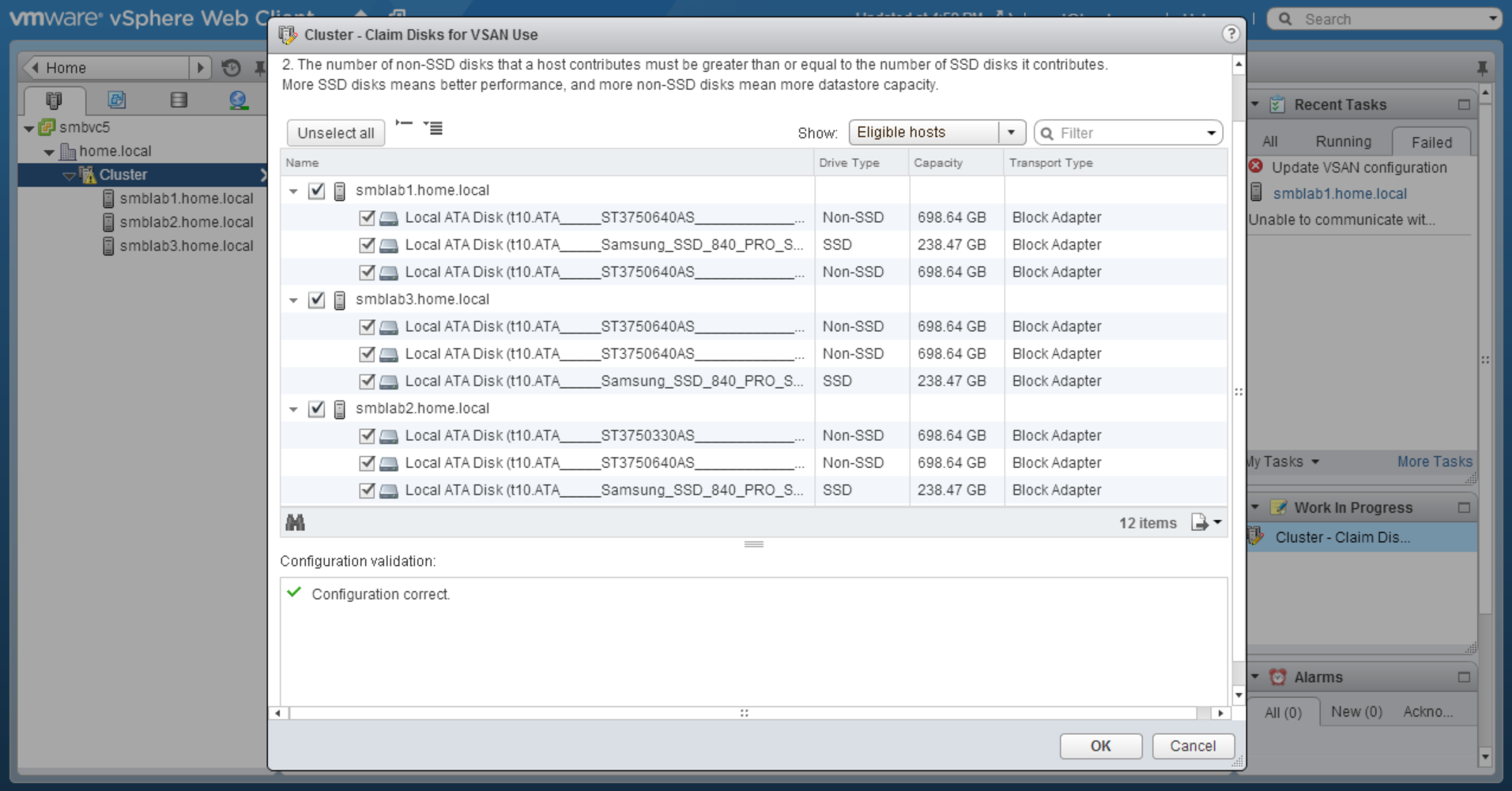
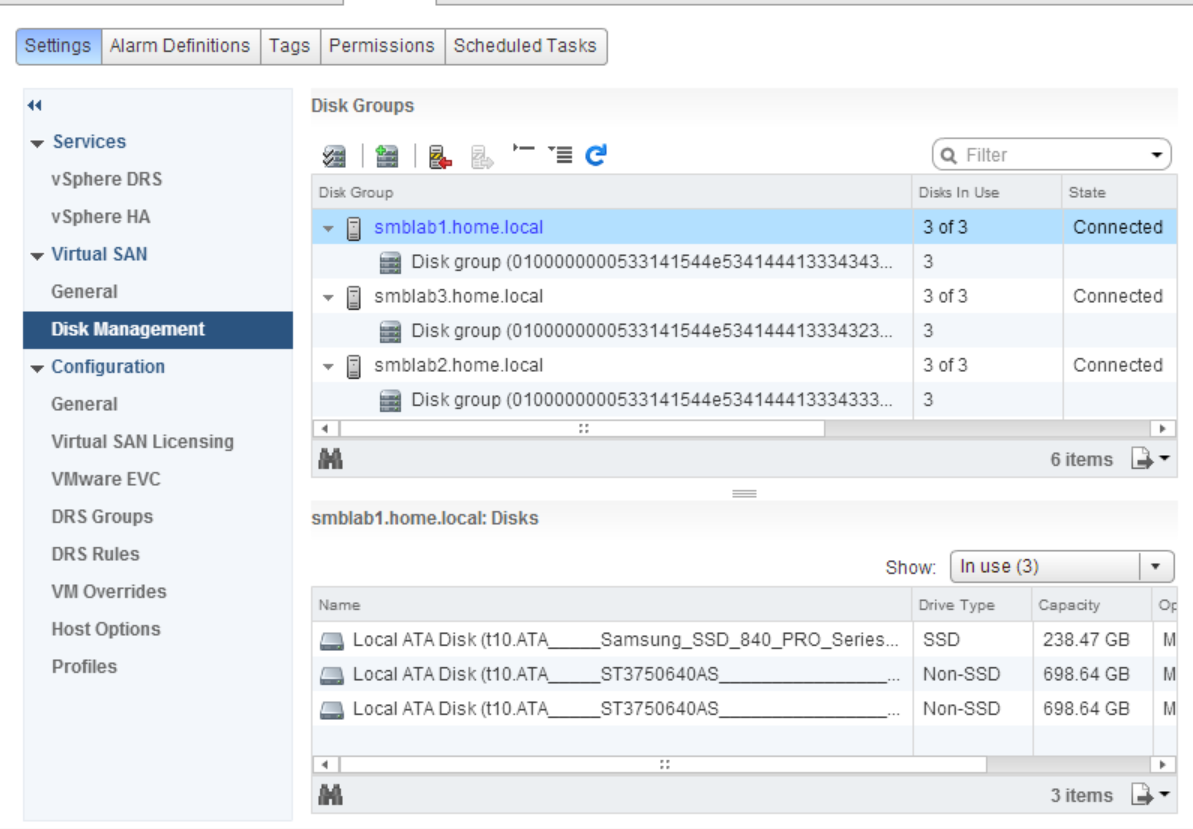
My vSAN is made of 3 identical ESXi hosts, with a single SSD Samsung 840 250GB, and two Seagate 750GB SATA drives. vSAN has a dedicated single 1GB connection, no jumbo frames used. (yes there could be bottlenecks at several spots, I haven’t dug that deeply, this is just a ‘first pass’ test)
The end result of this VERY BASIC test is this:
vSAN random reads were an average of 31 times faster than a single SATA disk
vSAN random writes were an average 9.1 times faster than a single SATA disk
More Details Below:
Regular single disk performance (just for a baseline before I begin vSAN testing)
Random Read (16k block size)
first test = 79 IOPS
second test = 79 IOPS
Random Write (16k block size)
first test = 127 IOPS
second test = 123 IOPS
vSAN disk performance with same VM vMotion to the vSAN
Random Read (16k block size)
first test = 2440 IOPS
second test = 2472 IOPS
Random Write (16k block size)
first test 1126 IOPS
second test 1158 IOPS
Commands used in fio:
sudo fio --directory=/mnt/volume --name fio_test --direct=1 --rw=randread --bs=16k --size=1G --numjobs=3 --time_based --runtime=120 —-group_reporting
sudo fio --directory=/mnt/volume --name fio_test --direct=1 --rw=randwrite --bs=16k --size=1G --numjobs=3 --time_based --runtime=120 —-group_reporting
I mentioned I did use IOMeter in windows, the initial results were very similar to the fio results above. I will post those once I have the time try each solution and go deeper into identifying bottlenecks and getting more detailed, adding more hosts, etc…